What are Tokens
Before we move on, there are some important LLM concepts you must understand.
The first one is the token.
Machines process human language differently than we do.
We, humans, split the sentence into words, map each word to a different meaning in our heads, and then understand the sentence as a whole.
But machines can't really "understand" the word, instead, they split the sentence into tokens.
A token can be as short as a single letter, as long as a single word, or part of a word, depending on the language and the tokenizer used by the model.
For example, the word "fantastic" might be a single token, while "unbelievable!" could be split into several tokens like "un", "bel", "ievable", and "!".
There are many visual tokenizer platforms you can use to test this, such as the GPT-Tokenizer Playground.
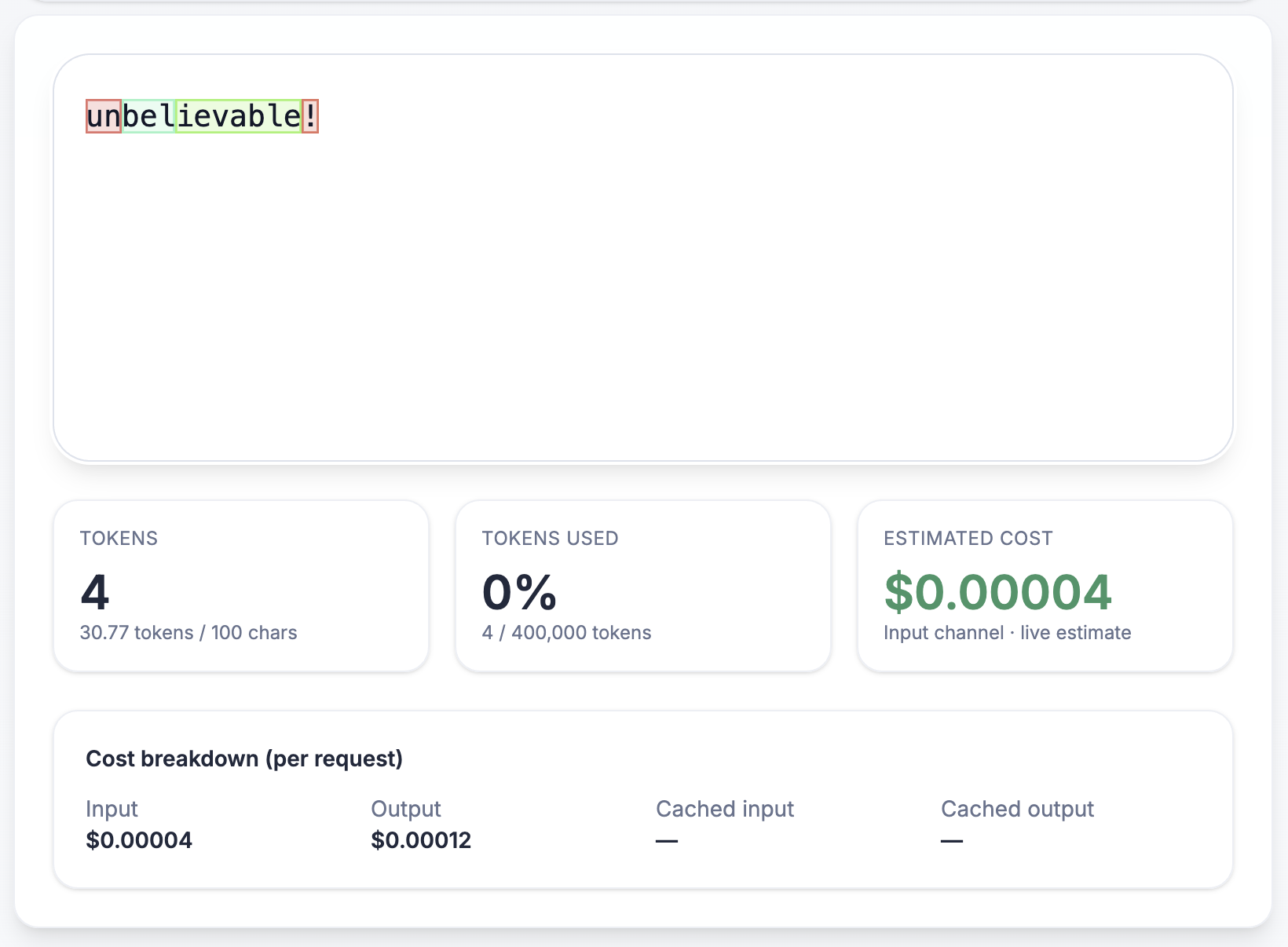
For the English language, one token is roughly 3/4 of a word on average.
Each token will then be converted into a number, aka the token ID, which the machine can understand and process.
Understanding tokens is important because this is how LLMs determine the cost and the maximum input/output size.